概率上下文无关语法(PCFG)
October 27, 2017
在 NLP 任务中,我们可以根据一组 grammar 规则来生成一个句子。
下面这个 grammar 例子表示,一个句子能够由名词短语 I 和动词短语 want a morning filght 组成;名词短语能够由代词 I 组成,或由名词 Los Angeles 组成等。
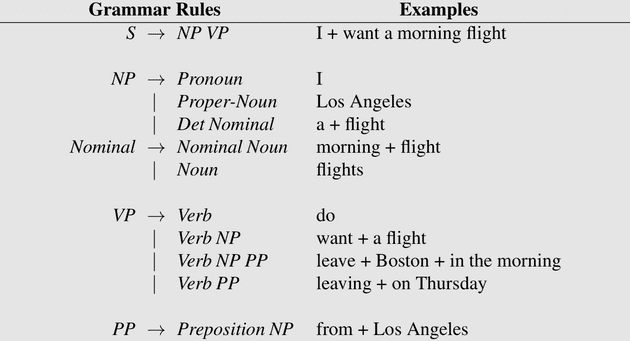
Context-Free Grammar(CFG)
什么是“上下文无关”?
考虑下图这个 parse tree(语法树):
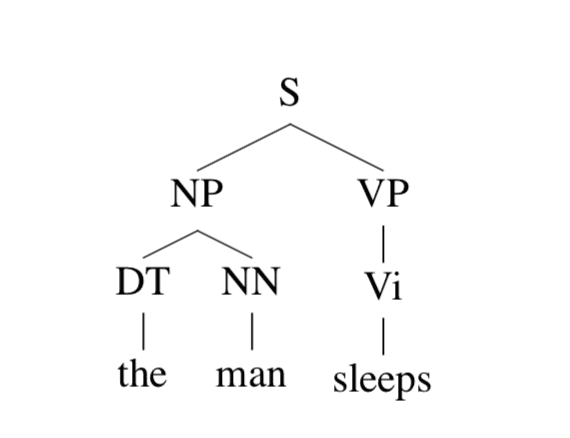
我们来模拟一下这句话生成的过程:
- S → NP VP
- S → NP VP → DT NN VP
- S → NP VP → DT NN VP → the NN VP
- S → NP VP → DT NN VP → the NN VP → the man VP
- S → NP VP → DT NN VP → the NN VP → the man VP → the man Vi
- S → NP VP → DT NN VP → the NN VP → the man VP → the man sleeps
在第一步到第二步时,DT 和 NN 的生成只与 NP 有关(根据 NP → DT NN 这条规则),而与 VP 无关,也就是说,所有规则的左侧只有一个符号,这种形式称为上下文无关。
CFG 定义
CFG 由一个四元组 N,Σ,R,S 组成。其中,
- N 是 non-terminal 符号的集合,理解为语法树中的非叶节点(S、NP……)
- Σ 是 terminal 符号的集合,也就是各个单词(叶节点 the、man、sleeps)
- R 代表 grammar 中的规则,如 S→ NP VP
- S 代表开始的标记,也就是语法树的根节点
上面例子的语法树是根据下面这个 grammar 生成的。由一句话和一个 grammar 生成 parse tree 的过程叫做 parsing。在这里由于句子是由 grammar 生成的,这种建模方法也被称为 generative grammar。

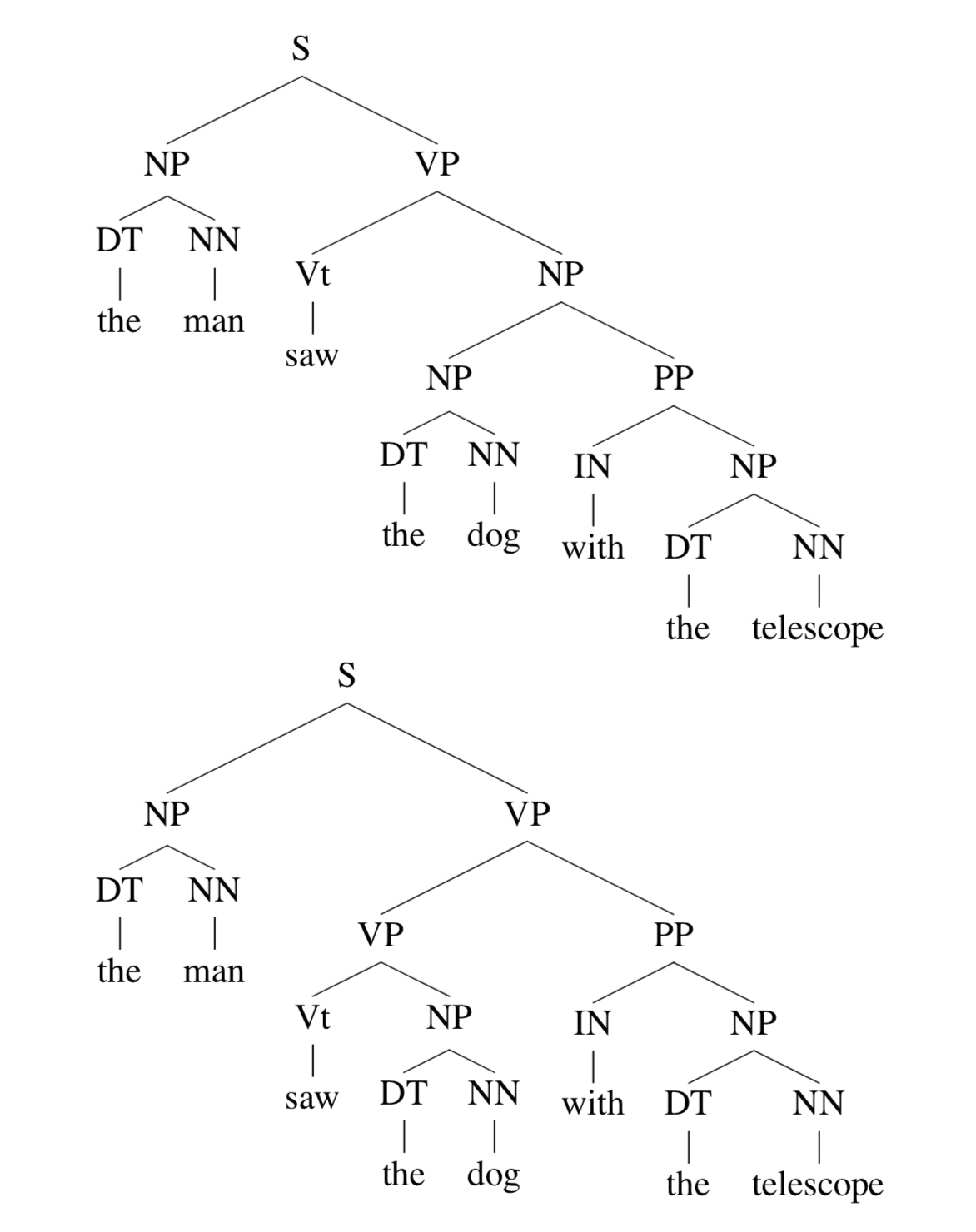
现在我们使用这个 grammar 来生成这样一句话:the man saw the dog with the telescope,会产生什么样的 parse tree 呢?
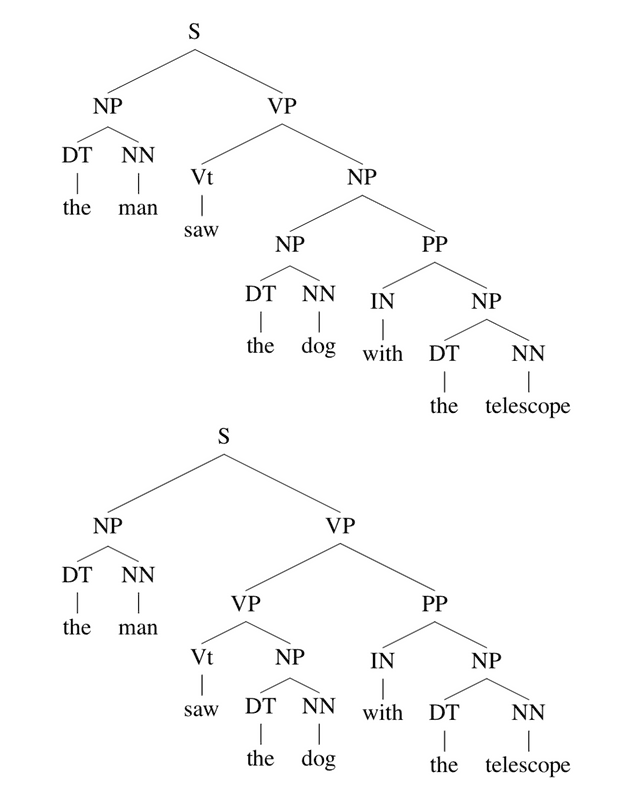
看,两个 parse tree 都是有效的,但却是两种语义。为了解决这种歧义的现象,我们在 CFG 中引入了概率的概念。
Probabilistic Context-Free Grammar(PCFG)
给定一个上下文无关语法 G,称 TG 为 grammar G 下的所有 parse tree 的集合,简写为 T。那么就有
t∈TG∑p(t)=1
因此如果知道了概率分布 p(t),那么我们就可以通过排序找到一句话最有可能的 parse tree。
PCFG 定义
-
一个上下文无关语法 G=(N,Σ,S,R)
-
对应每个规则 α→β∈R 的概率为 q(α→β),实际上这是在给定α 为规则左侧符号时,α→β 这条规则的条件概率。因此在任意 X∈N 时,有
α→β∈R:α=X∑q(α→β)=1
因此,如果一个 parse tree t∈TG 包含α1→β1,α2→β2,…,αn→βn这些规则,那么 t 在 PCFG 下的概率为
p(t)=i=1∏nq(αi→βi)

上图为一个 PCFG,可以验证其满足
α→β∈R:α=VP∑q(α→β)=q(VP→Vi)+q(VP→VtNP)+q(VP→VPPP)=0.3+0.5+0.2=1.0
如果 parse tree 是这样:
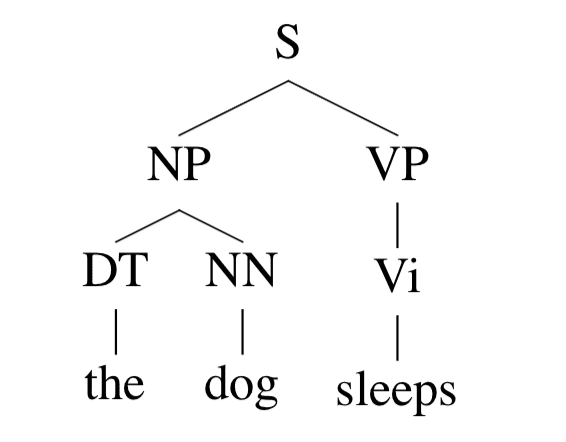
那么这个 parse tree 的概率就是
p(t)=q(S→NPVP)×q(NP→DTNN)×q(DT→the)×q(NN→dog)×q(VP→Vi)×q(Vi→sleeps)
References